知识图谱已成为人工智能和数据科学中一种强大而通用的方法,用于记录结构化信息,以促进成功的数据检索、推理和推理。本文探讨了最先进的知识图谱,包括构造、表示、查询、嵌入、推理、对齐和融合。
我们还讨论了知识图谱的许多应用,例如推荐引擎和问答系统。最后,为了为新的进展和研究机会铺平道路,我们探讨了该主题的问题和潜在的未来路线。
知识图谱通过提供灵活且可扩展的机制来表达实体和特征之间的复杂联系,彻底改变了信息的组织和使用方式。在这里,我们一般介绍知识图谱,它们的重要性以及它们在各个领域的潜在用途。
学习目标
理解知识图谱作为信息的结构化表示的概念和目的。
了解知识图谱的关键组件:节点、边和属性。
探索构建过程,包括数据提取和集成技术。
了解知识图谱嵌入如何将实体和关系表示为连续向量。
探索推理方法,从现有知识中推断出新的见解。
深入了解知识图谱可视化,以便更好地理解。
本文作为数据科学博客马拉松的一部分发布。
目录知识图谱可以在信息提取操作期间存储提取的信息。许多基础知识图实现都利用了三元组的概念,三元组是三个元素(主语、谓词和宾语)的集合,可以保存有关任何内容的信息。
图形是节点和边的集合。
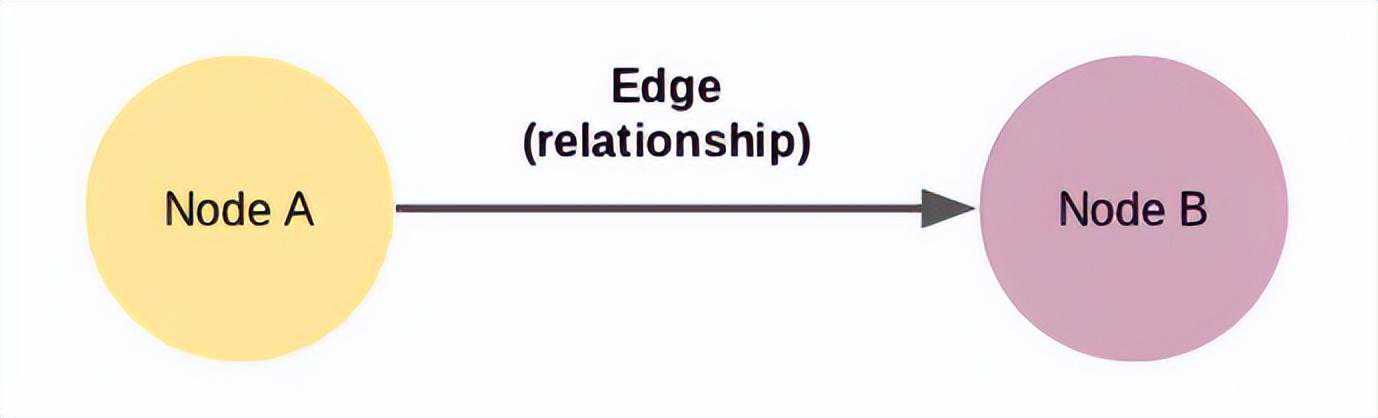
这是我们能设计的最小的知识图谱,也称为三元组。知识图谱有多种形式和大小。在这里,节点A和节点B是两个独立的东西。这些节点通过显示两个节点之间关系的边连接。
以下短语为例:
伦敦是英格兰的首都。威斯敏斯特位于伦敦。
我们稍后会看到一些基本的处理,但最初,我们将有两个三元组,如下所示:
(伦敦,成为首都,英格兰),(威斯敏斯特,定位,伦敦)
在此示例中,我们有三个不同的实体(伦敦、英国和威斯敏斯特)和两个关系(资本、位置)。构建知识图谱只需要网络中两个具有实体的相关节点和具有关系的顶点。生成的结构如下:手动创建知识图谱不可扩展。没有人会通过数百页来提取所有实体及其关系!
因为它们可以轻松地对数百甚至数千张论文进行分类,所以机器人比人类更适合处理这项工作。机器无法掌握自然语言的事实带来了另一个困难。在这种情况下使用自然语言处理(NLP)非常重要。
如果我们想从文本中创建知识图谱,让我们的计算机理解自然语言至关重要。使用NLP方法执行此操作,包括句子分割、依赖项解析、词性标记和实体识别。
importreimportpandasaspdimportbs4importrequestsimportspacyfromspacyimportdisplacynlp=('en_core_web_sm')_option('_colwidth',200)%matplotlibinlinedepencytagofprevioustokeninthesentenceprv_tok_text=""fortokinnlp(sent):chunk2check:_=="compound":prefix=:_.swith("mod")==True:modifier=_tok_dep=_prv_tok_text==Matcher()extractsubjectsource=[i[0]foriinentity_pairs]createadirected-graphfromadataframeG=_pandas_edgelist(kg_df,"source","target",edge_attr=True,create_using=())(figsize=(12,12))pos=_layout(G)(G,with_labels=True,node_color='skyblue',edge_cmap=,pos=pos)()让我们用一个小例子来绘制网络:
_graph=KnowledgeGraph()Addrelationsbetweenentitiesknowledge__relation("UnitedStates","Neighborof","Canada")knowledge__relation("UnitedStates","Neighborof","Mexico")knowledge__relation("France","Neighborof","Spain")knowledge__relation("France","Neighborof","Italy")knowledge__relation("China","Neighborof","India")knowledge__relation("China","Neighborof","Russia")Visualizetheknowledgegraphpos=_layout(knowledge_,seed=42)edge_labels=_edge_attributes(knowledge_,"label")(figsize=(8,6))(knowledge_,pos,with_labels=True,node_size=2000,node_color="skyblue",font_size=10)_networkx_edge_labels(knowledge_,pos,edge_labels=edge_labels,font_size=8)("KnowledgeGraph:CountriesandtheirCapitals")()
这不是我们想要的(但它仍然是一个相当的景象!我们发现我们已经生成了一个包含所有关系的图表。具有如此多关系或谓词的图形变得非常难以看到。
因此,最好只使用几个关键关系来可视化图形。我会一次处理一种关系。让我们从“组成”的关系开始:
G=_pandas_edgelist(kg_df[kg_df['edge']=="composedby"],"source","target",edge_attr=True,create_using=())(figsize=(12,12))pos=_layout(G,k=0.5)(G,with_labels=True,node_color='skyblue',node_size=1500,edge_cmap=,pos=pos)()

这是一个更好的图表。在这种情况下,箭头指向作曲家。在上图中,著名音乐作曲家与“配乐”、“电影配乐”和“音乐”等内容相关联。
让我们看一些额外的连接。现在我想为“写入者”关系绘制图形:
G=_pandas_edgelist(kg_df[kg_df['edge']=="writtenby"],"source","target",edge_attr=True,create_using=())(figsize=(12,12))pos=_layout(G,k=0.5)(G,with_labels=True,node_color='skyblue',node_size=1500,edge_cmap=,pos=pos)()

这个知识图谱为我们提供了一些惊人的数据。著名的作词家包括贾韦德·阿赫塔尔、克里希纳·柴坦尼亚和贾迪普·萨尼;这张图雄辩地描绘了他们的关系。
让我们看一下另一个关键谓词的知识图谱,“发布于”:
G=_pandas_edgelist(kg_df[kg_df['edge']=="releasedin"],"source","target",edge_attr=True,create_using=())(figsize=(12,12))pos=_layout(G,k=0.5)(G,with_labels=True,node_color='skyblue',node_size=1500,edge_cmap=,pos=pos)()

总之,知识图谱已成为人工智能和数据科学中一种强大而通用的工具,用于表示结构化信息,从而实现高效的数据检索、推理和推理。在本文中,我们探讨了强调知识图谱在不同领域的重要性和影响的要点。以下是关键点:
知识图谱以图形格式提供信息的结构化表示,其中包含节点、边和属性。
知识图谱推理允许根据现有知识推断新的事实和见解。
应用程序跨越多个领域,包括自然语言处理、推荐系统和语义搜索引擎。
知识图谱嵌入在连续向量中表示实体和关系,从而支持对图进行机器学习。
总之,知识图谱对于组织和理解大量相互关联的信息至关重要。随着研究和技术的进步,知识图谱无疑将在塑造人工智能、数据科学、信息检索和各行各业决策系统的未来方面发挥核心作用。
问题1.使用知识图谱有什么好处?
答:知识图谱可实现高效的数据检索、推理和推理。它们支持语义搜索,促进数据集成,并为构建推荐和问答系统等智能应用程序提供强大的基础。
问题2.知识图谱是如何构建的?
问题3.什么是知识图谱对齐?
答:知识图谱对齐是整合来自多个知识图谱或数据集的信息,以创建一个统一且相互关联的知识库。
问题4.知识图谱如何用于自然语言处理?
答:知识图谱通过提供上下文信息和实体之间的语义关系,改进实体识别、情感分析和问答系统来增强自然语言处理任务。
问题5.什么是知识图谱嵌入?
答:知识图谱嵌入将实体和关系表示为低维空间中的连续向量。它们用于捕获图中实体和关系的语义含义和结构信息。