从20世纪80年代和90年代华尔街出现所谓的“火箭科学家”以来,金融学已经发展成为一种应用数学学科。虽然早期金融学研究论文中出现的数学表达式和公式不多,但是这些表达式和公式已经成为当今金融学论文的主要组成部分,其他部分则是解释它们的文字。
本章介绍对金融学有用的一些数学工具,但是对每种工具的背景不做详细的介绍。这个主题有许多实用的图书,因此,本章的焦点是如何在Python中使用这些工具和技术。这些工具如下所示。
逼近法回归和插值是金融学中最常用的数学技术之一。
凸优化一些金融学科需要凸优化工具(例如,衍生品定价模型检验)。
积分金融(衍生品)资产的估值往往归结为积分计算。
符号数学Python提供SymPy。SymPy是一种强大的符号数学工具,例如,它可以解方程(组)。
11.1逼近法首先,是通常的导入工作:
In[1]:importnumpyasnpfrompylabimportplt,mplIn[2]:('seaborn')['']='serif'%matplotlibinline本节使用的主函数示例如下,由一个三角函数项和一个线性项组成:
In[3]:deff(x):(x)+0.5*x
重点是在给定区间内通过回归和插值求取该函数的近似值。首先,生成该函数的图形,以便更好地观察逼近法的效果。我们感兴趣的区间是[−2π,2π]。图11-1显示了该函数在()函数定义的固定区间上的图像。create_plot()是一个助手函数,可以创建本章多次要使用的同类图表:

图11-1示例函数图表
In[4]:defcreate_plot(x,y,styles,labels,axlabels):(figsize=(10,6))foriinrange(len(x)):(x[i],y[i],styles[i],label=labels[i])(axlabels[0])(axlabels[1])(loc=0)In[5]:x=(-2*,2*,50)❶In[6]:create_plot([x],[f(x)],['b'],['f(x)'],['x','f(x)'])
❶用于绘图和计算的x值。
11.1.1回归回归是相当高效的函数近似值计算工具。它不仅适用于求取一维函数的近似值,在更高维度上也很有效。得出回归结果所需要的数值化方法很容易实现,执行也很快速。本质上,回归的任务是在给定一组所谓“基函数”bd,d∈{1,…,D}的情况下,根据公式11-1找出最优参数
,…
,其中对于i∈{1,…I}观察点,yi≡f(xi)。xi可以视为自变量观测值,yi可视为因变量观测值(从函数或者统计的意义上说)。
公式11-1.最小化回归问题
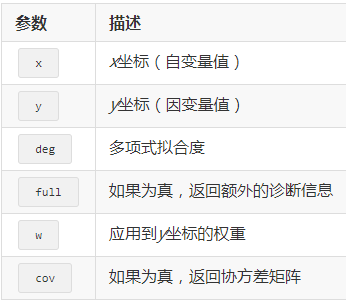
最简单的情况是以单项式作为基函数——也就是说,b1=1,b2=x,b3=x2,b4=x3,…在这种情况下,NumPy有可以确定最优参数(())和通过一组输入值求取近似值(())的内建函数。
表11-1列出了()函数的参数。在()返回的最优回归相关系数ρ基础上,(ρ,x)返回x坐标的回归值。
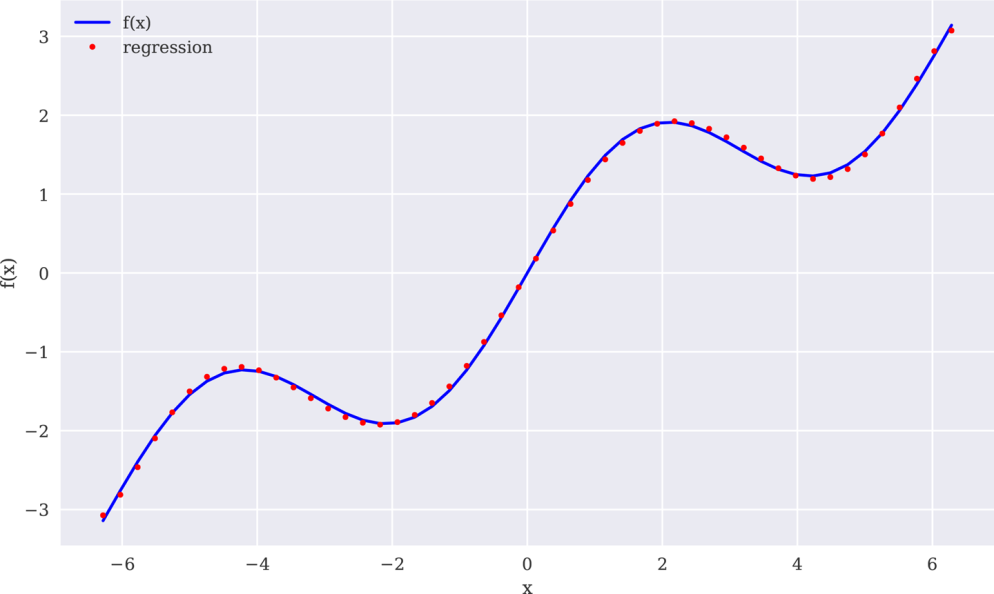
表11-1()函数参数
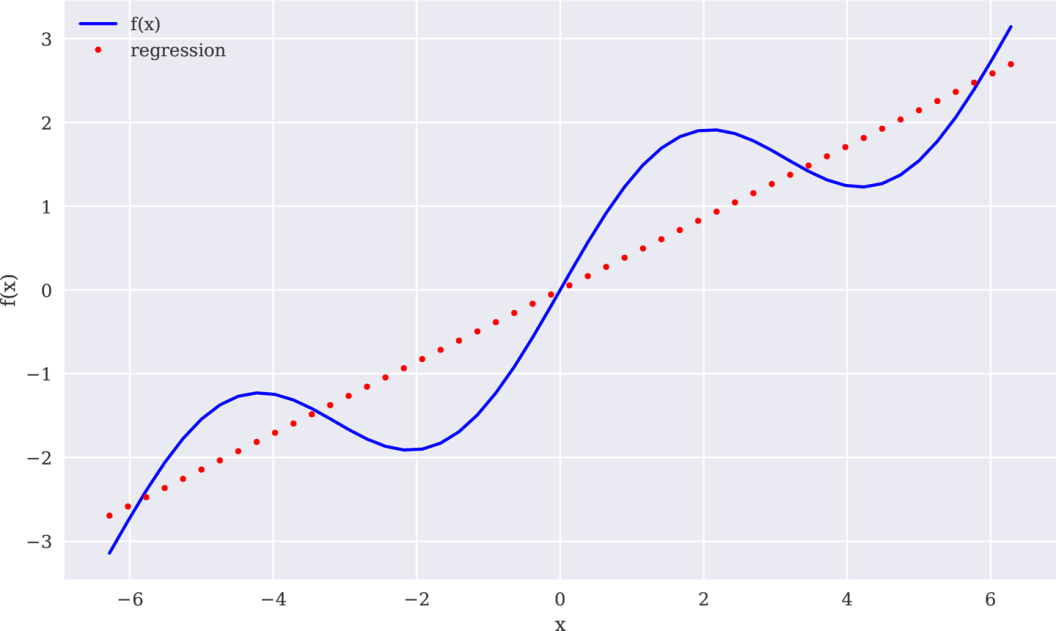
典型向量化风格的()和()线性回归(deg=1)的应用方式如下。由于回归估算值保存在ry数组中,所以我们可以如图11-2那样比较回归结果和原始函数。当然,线性回归无法处理示例函数的sin部分:
In[7]:res=(x,f(x),deg=1,full=True)❶In[8]:res❷Out[8]:(array([4.28841952e-01,-1.31499950e-16]),array([21.03238686]),2,array([1.,1.]),1.1102230246251565e-14)In[9]:ry=(res[0],x)❸In[10]:create_plot([x,x],[f(x),ry],['b','r.'],['f(x)','regression'],['x','f(x)'])
❶线性回归步骤。
❷完整的结果:回归参数、残差、有效秩、奇异值和相对条件数。
❸使用回归参数求值。
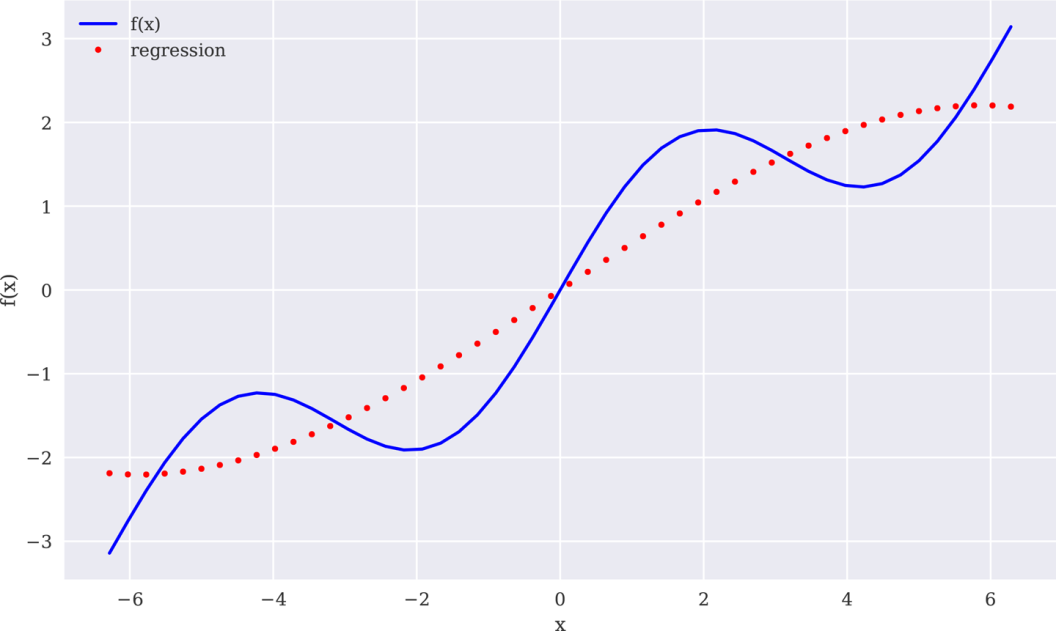
图11-2线性回归
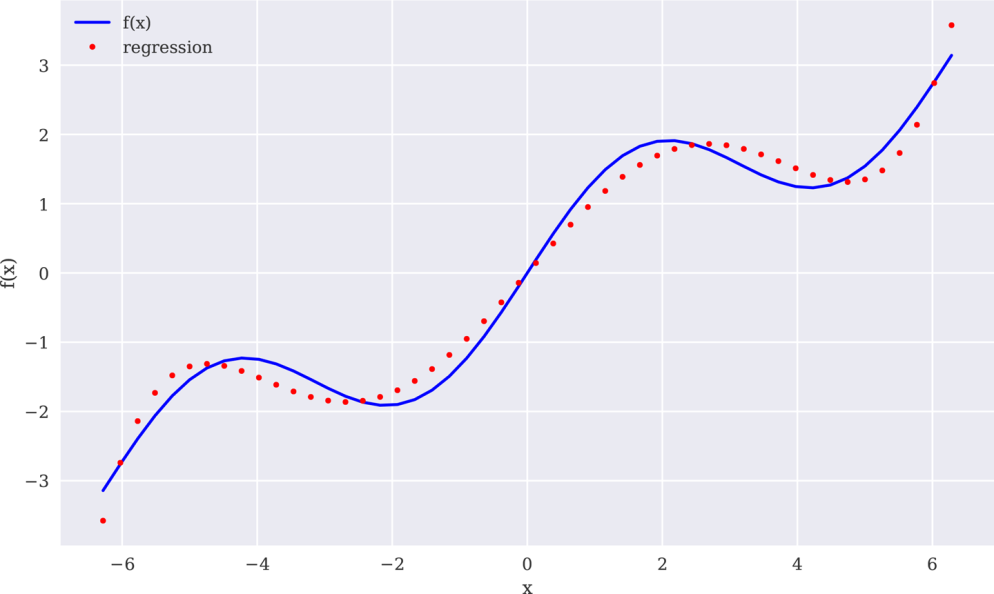
为了处理示例函数的sin部分,必须使用更高次的单项式。下一个回归试图使用5次单项式作为基函数。果不其然,回归结果(如图11-3所示)看上去更接近原始函数。但是,它还远称不上完美:
In[11]:reg=(x,f(x),deg=5)ry=(reg,x)In[12]:create_plot([x,x],[f(x),ry],['b','r.'],['f(x)','regression'],['x','f(x)'])
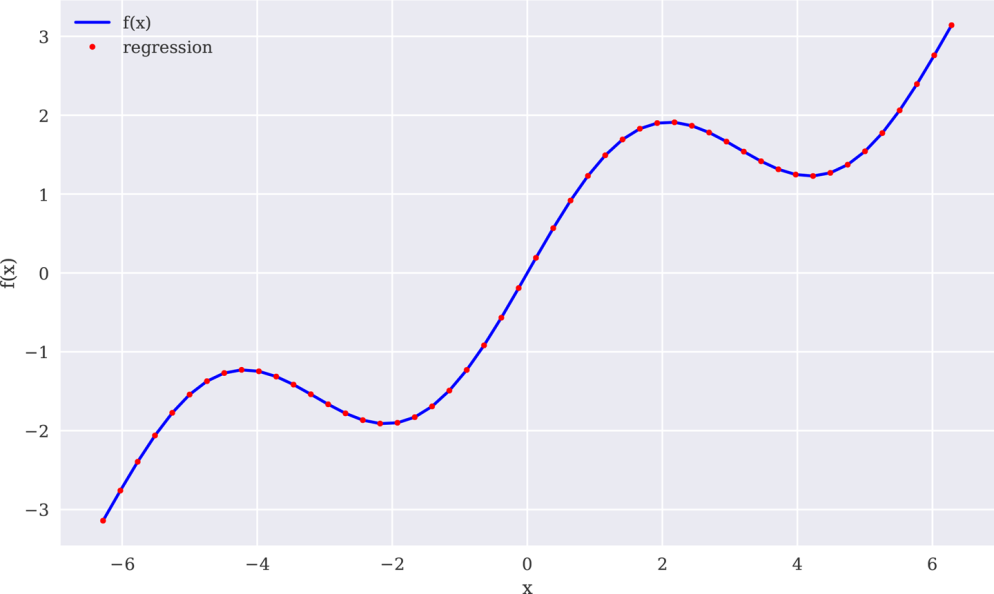
图11-3使用最高5次的单项式进行回归
最后一次尝试使用7次的单项式作为基函数来计算示例函数的近似值。这次的结果如图11-4所示,相当有说服力:
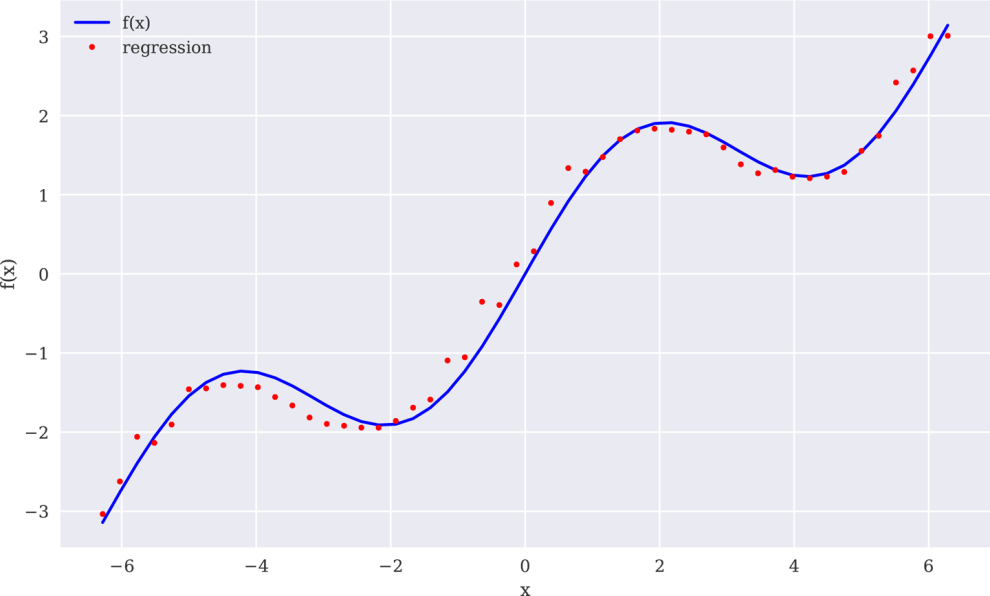
图11-47次单项式回归
In[13]:reg=(x,f(x),7)ry=(reg,x)In[14]:(f(x),ry)❶Out[14]:FalseIn[15]:((f(x)-ry)**2)❷Out[15]:0.00517689In[16]:create_plot([x,x],[f(x),ry],['b','r.'],['f(x)','regression'],['x','f(x)'])
❶检查函数和回归值是否相同(至少接近)。
❷根据函数值计算回归值均方差(MSE)。
2.单独的基函数一般来说,当您选择更好的基函数组时,可以得到更好的回归结果,例如利用对函数的认识进行近似值计算。在这种情况下,单独的基函数必须通过一个矩阵方法定义(也就是使用NumPy的ndarray对象)。首先,例子中的多项式最高为3次(图11-5)。本例的核心函数是():
In[17]:matrix=((3+1,len(x)))❶matrix[3,:]=x**3❷matrix[2,:]=x**2❷matrix[1,:]=x❷matrix[0,:]=1❷In[18]:reg=(,f(x),rcond=None)[0]❸In[19]:(4)❹Out[19]:array([0.,0.5628,-0.,-0.0054])In[20]:ry=(reg,matrix)❺In[21]:create_plot([x,x],[f(x),ry],['b','r.'],['f(x)','regression'],['x','f(x)'])
❶基函数值(矩阵)所用的ndarray对象。
❷从常数到三次基函数值。
❸回归步骤。
❹最优回归参数。
❺函数值的回归估算。
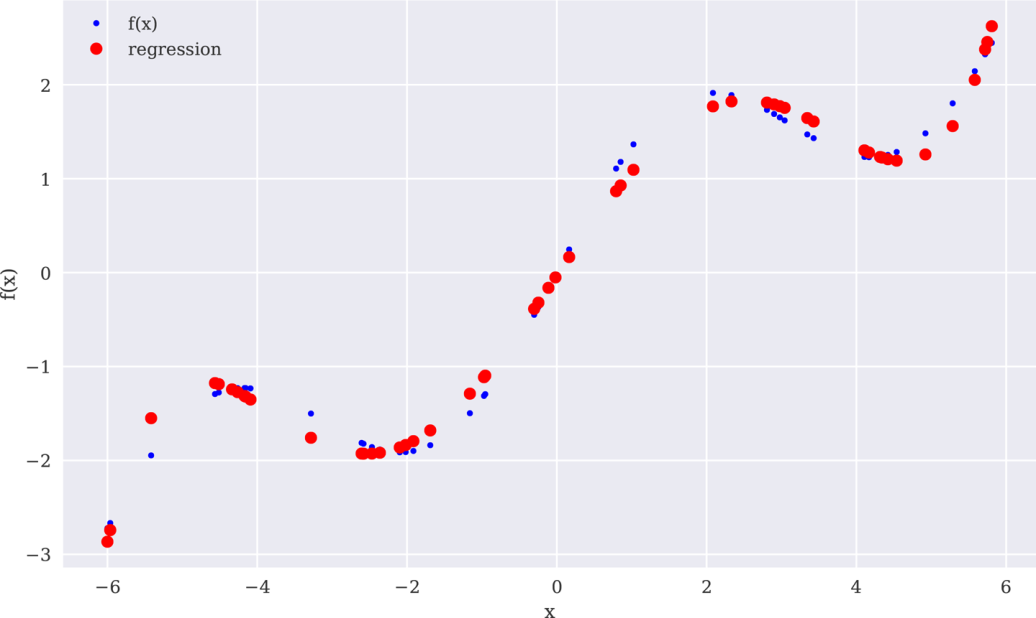
图11-5有单独基函数的回归
根据前面单项式的经验,图11-5中的结果并不真的如预期那么好。使用更通用的方法可以让我们利用对示例函数的认识。我们知道函数中有一个sin部分。因此,在基函数中包含一个正弦函数是有意义的。简单起见,我们替换最高次的单项式。现在的拟合很完美,如图11-6所示:
In[22]:matrix[3,:]=(x)❶In[23]:reg=(,f(x),rcond=None)[0]In[24]:(4)❷Out[24]:array([0.,0.5,0.,1.])In[25]:ry=(reg,matrix)In[26]:(f(x),ry)❸Out[26]:TrueIn[27]:((f(x)-ry)**2)❸Out[27]:3.404735992885531e-31In[28]:create_plot([x,x],[f(x),ry],['b','r.'],['f(x)','regression'],['x','f(x)'])
❶新的基函数利用关于示例函数的知识。
❷最优回归参数恢复原始参数。
❸现在,回归产生了完美的拟合。
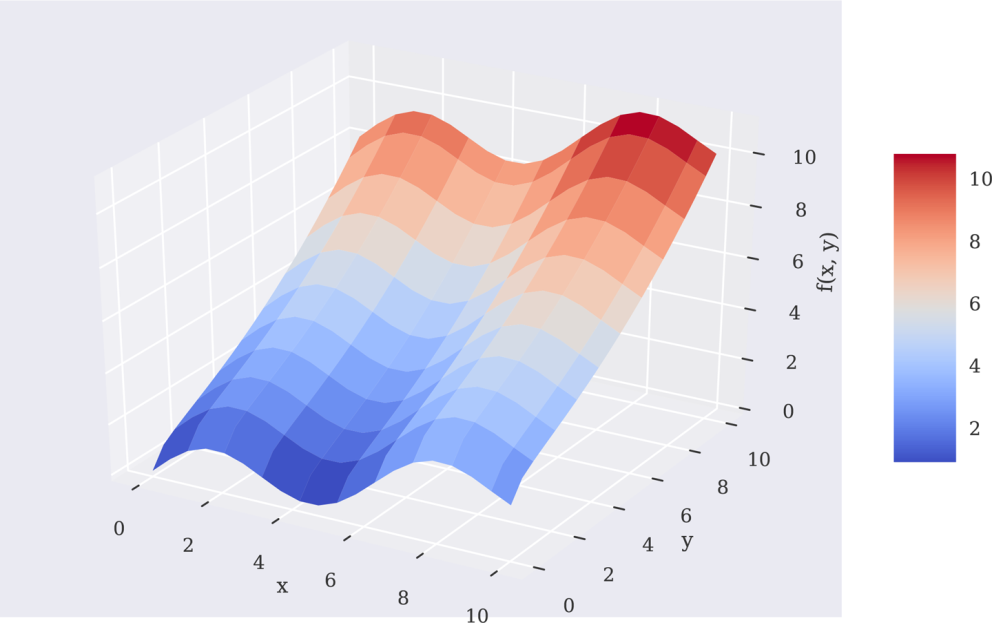
图11-6使用正弦基函数的回归
3.有噪声的数据回归对于有噪声的数据同样能够很好的处理,这种数据来自于模拟或者(不完善的)测量。为了阐述这个要点,我们生成同样具有噪声的自变量观测值和因变量观测值。图11-7表明,回归结果比有噪声的数据点更接近原始函数。在某种意义上,回归在一定程度上平均了噪声:
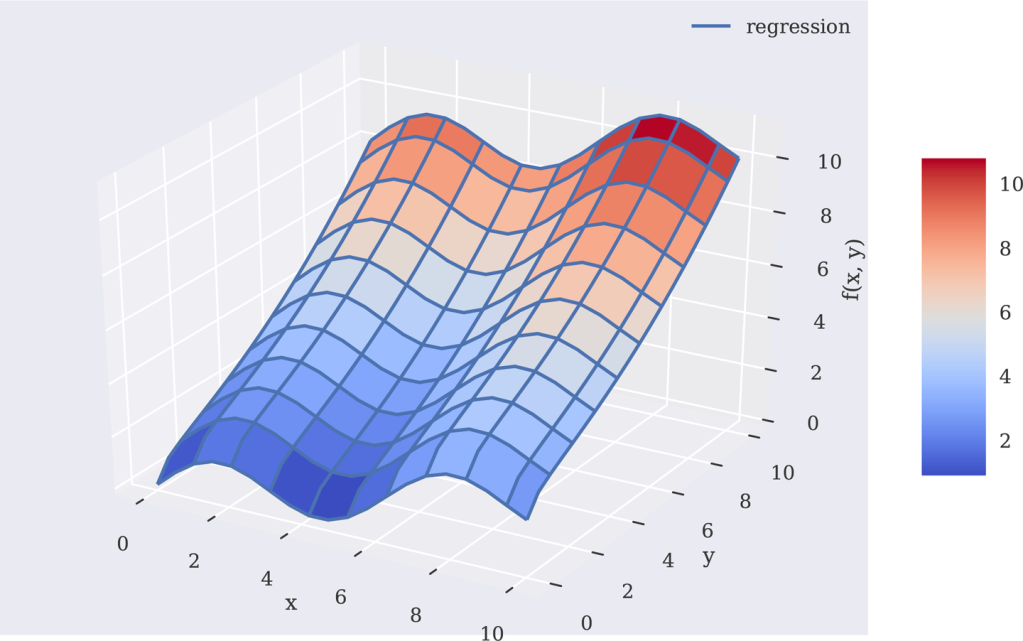
图11-7使用有噪声数据的回归
In[29]:xn=(-2*,2*,50)❶xn=xn+0.15*_normal(len(xn))❷yn=f(xn)+0.25*_normal(len(xn))❸In[30]:reg=(xn,yn,7)ry=(reg,xn)In[31]:create_plot([x,x],[f(x),ry],['b','r.'],['f(x)','regression'],['x','f(x)'])
❶新的x确定值。
❷在x值中引入噪声。
❸在y值中引入噪声。
4.未排序数据回归的另一个重要特点是,它可以无缝地处理未排序数据。前面的例子都依赖于经过排序的x数据,情况并不总是这样的。为了说明这一点,我们随机生成自变量数据点。在这种情况下,仅靠从视觉上检查原始数据很难识别出任何结构:
In[32]:xu=(50)*4**❶yu=f(xu)In[33]:print(xu[:10].round(2))❶print(yu[:10].round(2))❶[-4.17-0.11-1.912.333.34-0.965.814.92-4.56-5.42][-1.23-0.17-1.91.891.47-1.292.451.48-1.29-1.95]In[34]:reg=(xu,yu,5)ry=(reg,xu)In[35]:create_plot([xu,xu],[yu,ry],['b.','ro'],['f(x)','regression'],['x','f(x)'])
❶随机化x值。
和有噪声数据一样,回归方法不关心观测点的顺序。这在研究公式11-1所示的最小化问题的结构时很明显。从图11-8中显示的结果来看也很明显。
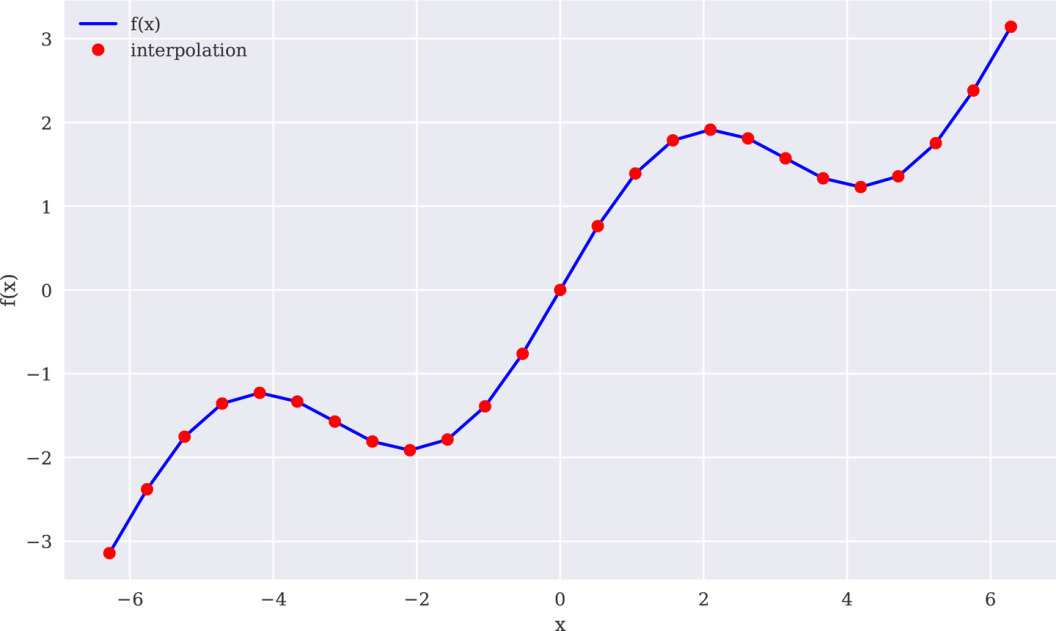
图11-8使用未排序数据的回归
5.多维最小二乘回归方法的另一个优点是,不需要太多的修改就可以用于多维的情况。接下来以fm()函数为例进行讲解:
In[36]:deffm(p):x,y=(x)+0.25*x+(y)+0.05*y**2
为了正确地可视化这个函数,我们需要自变量数据点的网格(在两个维度上)。图11-9根据以x、y、z表示的自变量和因变量二维数据点网格,显示了fm()函数的形状:
In[37]:x=(0,10,20)y=(0,10,20)X,Y=(x,y)❶In[38]:Z=fm((X,Y))x=()❷y=()❷In[39]:frommpl_❸In[40]:fig=(figsize=(10,6))ax=(projection='3d')surf=_surface(X,Y,Z,rstride=2,cstride=2,cmap='coolwarm',linewidth=0.5,antialiased=True)_xlabel('x')_ylabel('y')_zlabel('f(x,y)')(surf,shrink=0.5,aspect=5)❶从一维ndarray对象生成二维ndarray对象(网格)。
❷从二维ndarray对象得到一维ndarray对象。
❸必要时从matplotlib导入3D绘图功能。
图11-9使用两个参数的函数
为了获得好的回归结果,我们将应用基本函数集,包括fm()函数、()和()函数。图11-10直观展示了完美的回归结果:
In[41]:matrix=((len(x),6+1))matrix[:,6]=(y)❶matrix[:,5]=(x)❷matrix[:,4]=y**2matrix[:,3]=x**2matrix[:,2]=ymatrix[:,1]=xmatrix[:,0]=1In[42]:reg=(matrix,fm((x,y)),rcond=None)[0]In[43]:RZ=(matrix,reg).reshape((20,20))❸In[44]:fig=(figsize=(10,6))ax=(projection='3d')surf1=_surface(X,Y,Z,rstride=2,cstride=2,cmap=,linewidth=0.5,antialiased=True)❹surf2=_wireframe(X,Y,RZ,rstride=2,cstride=2,label='regression')❺_xlabel('x')_ylabel('y')_zlabel('f(x,y)')()(surf,shrink=0.5,aspect=5)❶用于y参数的()函数。
❷用于x参数的()函数。
❸将回归结果转化为网格结构。
❹绘制原始函数曲面。
❺绘制回归曲面。
图11-10双参数函数的回归曲面
11.1.2插值与回归相比,插值(例如,3次样条插值)在数学上更为复杂。它还被限制在低维度问题上。给定一组有序的观测点(按照x维排序),基本的思路是在两个相邻数据点之间进行回归,这样做不仅产生的分段插值函数完全匹配数据点,而且函数在数据点上连续可微分。连续可微分性需要至少3阶插值——也就是3次样条插值。然而,这种方法一般也适用于4次或者线性样条插值。
下面的代码可实现线性样条插值,结果如图11-11所示:
In[45]:❶In[46]:x=(-2*,2*,25)In[47]:deff(x):(x)+0.5*xIn[48]:ipo=(x,f(x),k=1)❷In[49]:iy=(x,ipo)❸In[50]:(f(x),iy)❹Out[50]:TrueIn[51]:create_plot([x,x],[f(x),iy],['b','ro'],['f(x)','interpolation'],['x','f(x)'])
❶从SciPy导入必要的子库。
❷实现线性样条插值。
❸得出内插值。
❹检查内插值是否(足够)接近函数值。
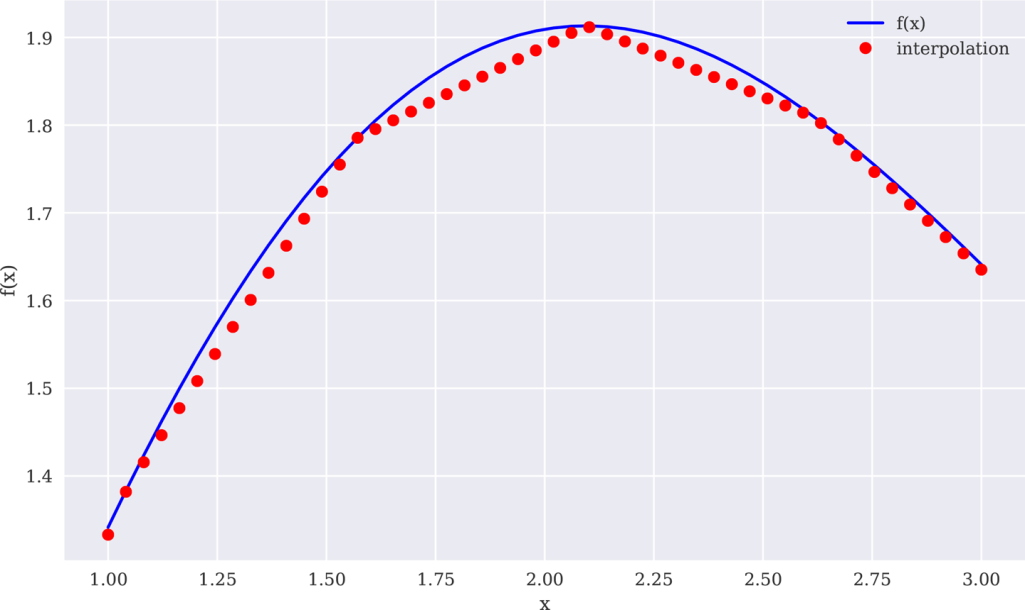
图11-11线性样条插值(完整数据集)
如果有按照x值排序的一组数据点,那么应用本身也和使用()和()函数一样简单。在本例中,它们对应的函数是()和()。表11-2列出了()函数的主要参数。
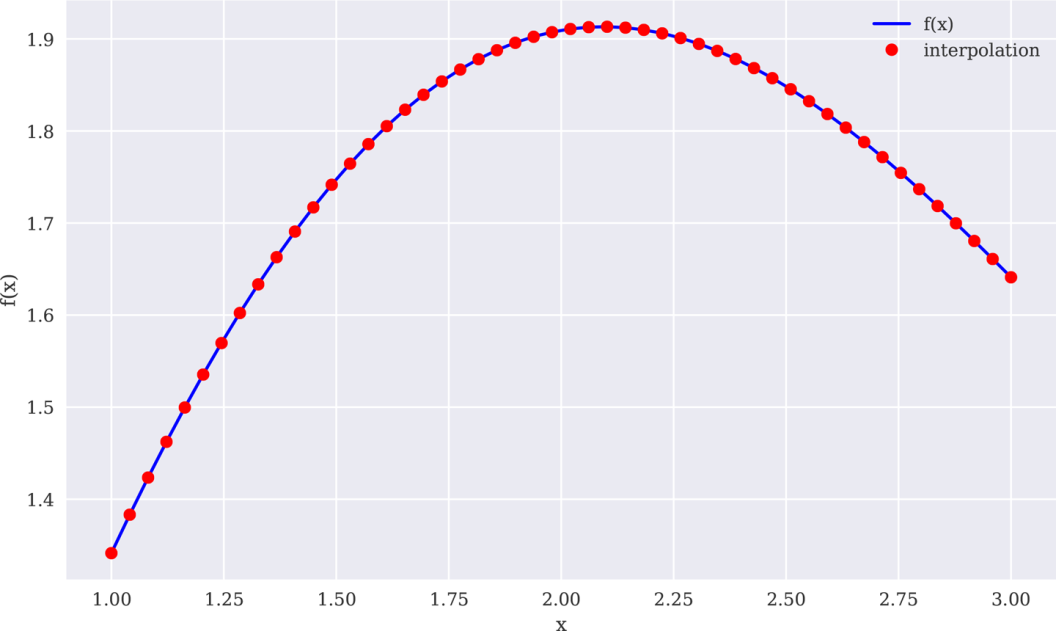
表11-2()函数参数
表11-3列出()函数的参数。
表11-3()函数参数
样条插值在金融学中往往用于估算未包含在原始观测点中的自变量数据点的因变量值。为此,在下个例子中选择一个更小的区间,仔细观察一次样条插入的值。图11-12说明,插值函数确实可以线性地在两个观测点之间插值。对于某些应用,这可能不够精确。此外,很明显函数在原始数据点上不是连续可微分的——这是另一个不足:
In[52]:xd=(1.0,3.0,50)❶iyd=(xd,ipo)In[53]:create_plot([xd,xd],[f(xd),iyd],['b','ro'],['f(x)','interpolation'],['x','f(x)'])
❶具有更多数据点的较小区间。
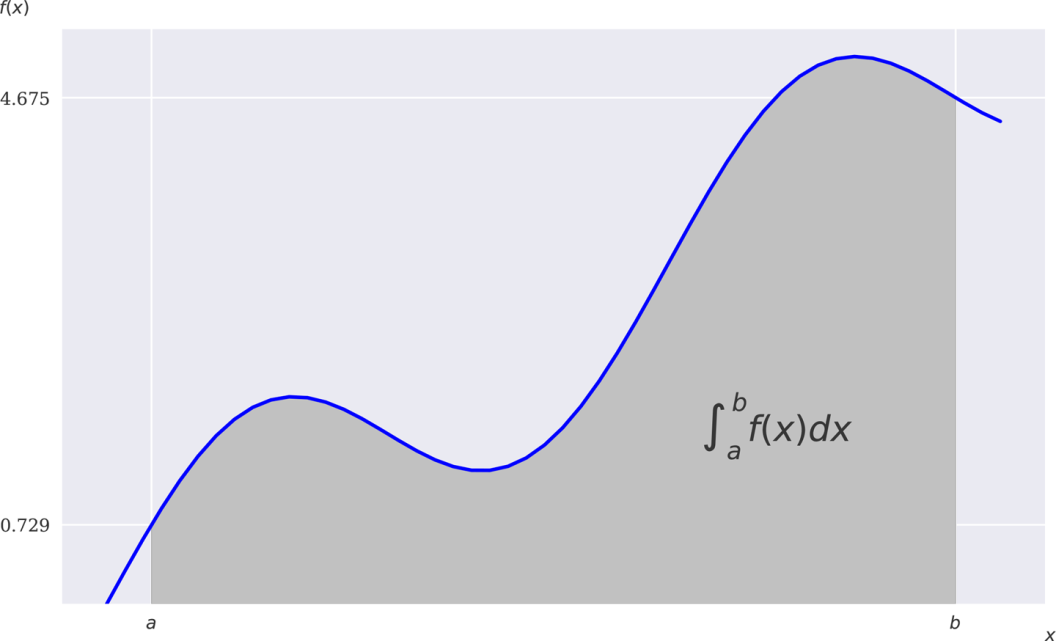
图11-12线性样条插值(数据子集)
重复整个练习,这次使用3次样条,结果明显改善(见图11-13):
In[54]:ipo=(x,f(x),k=3)❶iyd=(xd,ipo)❷In[55]:(f(xd),iyd)❸Out[55]:FalseIn[56]:((f(xd)-iyd)**2)❹Out[56]:1.36892e-08In[57]:create_plot([xd,xd],[f(xd),iyd],['b','ro'],['f(x)','interpolation'],['x','f(x)'])
❶完整数据集上的3次样条插值。
❷结果应用到更小的时间间隔。
❸插值仍然不完美。
❹但好于从前。

图11-13三次样条插值(数据子集)
11.2凸优化在金融学和经济学中,凸优化起着重要的作用。这方面的例子包括根据市场数据校准期权定价模型,或者代理人效用函数的优化。我们以下面定义的函数fm()为例进行这种优化:
In[58]:deffm(p):x,y=preturn((x)+0.05*x**2+(y)+0.05*y**2)
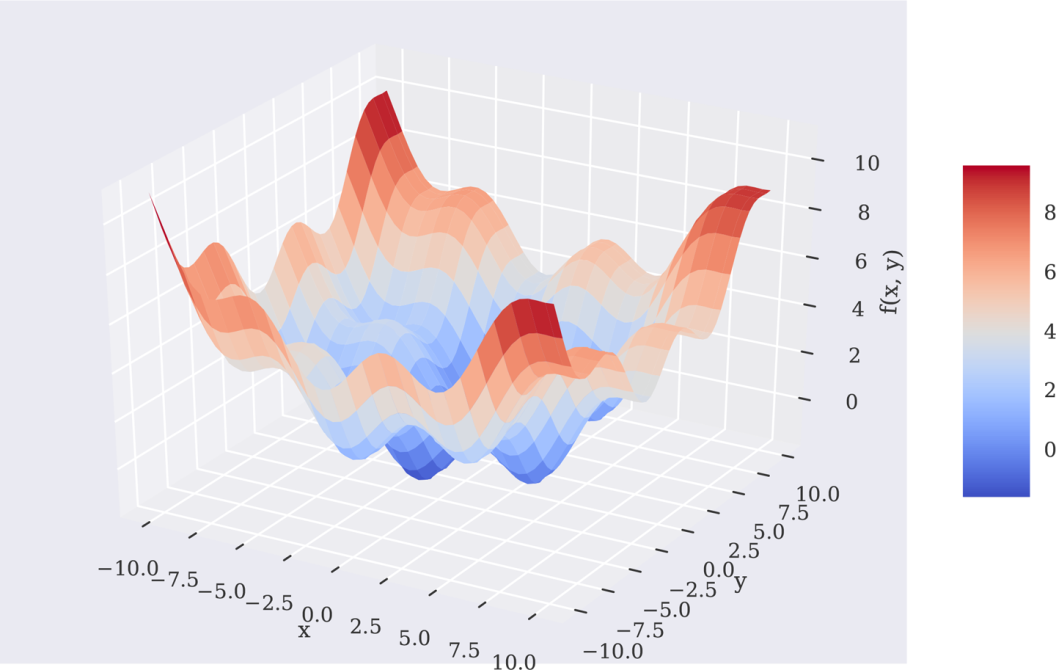
图11-14展示了上述函数在定义的x和y区间内的图形。从图11-14可以看出这个函数有多个局部极小值。从这个特定的图形表现中无法真正确认全局最小值是否存在:
In[59]:x=(-10,10,50)y=(-10,10,50)X,Y=(x,y)Z=fm((X,Y))In[60]:fig=(figsize=(10,6))ax=(projection='3d')surf=_surface(X,Y,Z,rstride=2,cstride=2,cmap='coolwarm',linewidth=0.5,antialiased=True)_xlabel('x')_ylabel('y')_zlabel('f(x,y)')(surf,shrink=0.5,aspect=5)图11-14以两个参数最小化的函数
11.2.1全局优化下面将实现全局最小化和局部最小化。所应用的()和()函数来自()。
为了仔细观察这些最小过程的幕后操作,使用以下代码为原函数增补可以输出当前参数值和函数值的选项。这使我们可以跟踪过程的所有相关信息:
In[61]:❶In[62]:deffo(p):x,y=pz=(x)+0.05*x**2+(y)+0.05*y**2ifoutput==True:print('%8.4f|%8.4f|%8.4f'%(x,y,z))❷returnzIn[63]:output=(fo,((-10,10.1,5),(-10,10.1,5)),finish=None)❸-10.0000|-10.0000|11.0880-10.0000|-10.0000|11.0880-10.0000|-5.0000|7.7529-10.0000|0.0000|5.5440-10.0000|5.0000|5.8351-10.0000|10.0000|10.0000-5.0000|-10.0000|7.7529-5.0000|-5.0000|4.4178-5.0000|0.0000|2.2089-5.0000|5.0000|2.5000-5.0000|10.0000|6.66490.0000|-10.0000|5.54400.0000|-5.0000|2.20890.0000|0.0000|0.00000.0000|5.0000|0.29110.0000|10.0000|4.45605.0000|-10.0000|5.83515.0000|-5.0000|2.50005.0000|0.0000|0.29115.0000|5.0000|0.58225.0000|10.0000|4.747110.0000|-10.0000|10.000010.0000|-5.0000|6.664910.0000|0.0000|4.456010.0000|5.0000|4.747110.0000|10.0000|8.9120Out[63]:array([0.,0.])❶从SciPy导入必要的子库。
❷如果output=True,打印信息。
❸暴力优化。
根据函数的初始参数,最优参数值为x=y=0。快速检查上述输出可以看出,结果函数值也为0。你可能倾向于接受这一结果为全局优化。然而,第一次参数化相当粗糙,对两个输入参数均使用5的步长。现在进行显著的细化,以得到更好的结果,同时也说明上述解决方案不是最优的:
In[64]:output=Falseopt1=(fo,((-10,10.1,0.1),(-10,10.1,0.1)),finish=None)In[65]:opt1Out[65]:array([-1.4,-1.4])In[66]:fm(opt1)Out[66]:-1.7748994599769203
最优参数值现在为x=y=-1.4,全局优化的最小函数值大约为-1.7749。
11.2.2局部优化接下来的局部凸优化需要用到全局优化的结果。Scofmin()函数的输入是需要最小化的函数和起始参数值。可选的参数值是输入参数宽容度和函数值宽容度,以及最大迭代及函数调用次数。局部优化了进一步改善结果:
In[67]:output=Trueopt2=(fo,opt1,xtol=0.001,ftol=0.001,maxiter=15,maxfun=20)❶-1.4000|-1.4000|-1.7749-1.4700|-1.4000|-1.7743-1.4000|-1.4700|-1.7743-1.3300|-1.4700|-1.7696-1.4350|-1.4175|-1.7756-1.4350|-1.3475|-1.7722-1.4088|-1.4394|-1.7755-1.4438|-1.4569|-1.7751-1.4328|-1.4427|-1.7756-1.4591|-1.4208|-1.7752-1.4213|-1.4347|-1.7757-1.4235|-1.4096|-1.7755-1.4305|-1.4344|-1.7757-1.4168|-1.4516|-1.7753-1.4305|-1.4260|-1.7757-1.4396|-1.4257|-1.7756-1.4259|-1.4325|-1.7757-1.4259|-1.4241|-1.7757-1.4304|-1.4177|-1.7757-1.4270|-1.4288|-1.7757Warning:[68]:opt2Out[68]:array([-1.42702972,-1.42876755])In[69]:fm(opt2)Out[69]:-1.7757246992239009
❶局部凸优化。
在许多凸优化问题中,建议在局部优化之前进行全局优化。主要原因是局部凸优化算法很容易陷入某个局部最小值(所谓的“盆地跳跃”(basinhopping)),而忽略“更好”的局部最小值和全局最小值。下面可以看到,将初始参数化设置为x=y=2可得出高于0的“最小”值:
In[70]:output=(fo,(2.0,2.0),maxiter=250):0.015826Iterations:46Functionevaluations:86Out[70]:array([4.2710728,4.27106945])
11.2.3有约束优化
到目前为止,我们只考虑了无约束优化问题,但是许多类型的经济学或者金融学优化问题都有一个或者多个约束条件。这些约束可能采取等式或者不等式等正规形式。
举个简单的例子,考虑可能投资两种高风险证券(希望效用最大化)的投资者的效用最大化问题。两种证券今天的价格为qa=qb=10。一年之后,状态u下它们的收益分别为15美元和5美元,而在状态d下收益分别为5美元和12美元。两种状态出现的可能性相同。两种证券的向量收益分别记为ra和rb。
假设投资者的投资预算为w0=100美元,根据效用函数
得出未来的财富效率,其中w是可用的财富(以美元计算)。公式11-2是最优化问题的公式,其中a、b是投资者购买的证券数量。
公式11-2预期效用最大化问题
代入所有数值化假设,就得到公式11-3。注意,我们还对负数的预期效用最小化做了更改。
公式11-3预期效用最大化问题
我们使用()函数解决上述问题。除了需要最小化的函数之外,这个函数还将公式、不等式(以字典对象列表的形式)和参数范围(以元组对象元组的形式)作为输入。我们可以将公式11-3通过如下代码实现:
In[71]:importmathIn[72]:defEu(p):❶s,b=preturn-(0.5*(s*15+b*5)+0.5*(s*5+b*12))In[73]:cons=({'type':'ineq','fun':lambdap:100-p[0]*10-p[1]*10})❷In[74]:bnds=((0,1000),(0,1000))❸In[75]:result=(Eu,[5,5],method='SLSQP',bounds=bnds,constraints=cons)❹❶为了最大化预期效用而最小化的函数。
❷字典对象形式的不等式约束。
❸参数边界值(选择为足够宽)。
❹约束优化。
result对象包含所有相关信息。对于最小函数值,必须记得恢复符号:
In[76]:resultOut[76]:fun:-9.700883611487832jac:array([-0.48508096,-0.48489535])message:'Optimizationterminatedsuccessfully.'nfev:21nit:5njev:5status:0success:Truex:array([8.02547122,1.97452878])In[77]:result['x']❶Out[77]:array([8.02547122,1.97452878])In[78]:-result['fun']❷Out[78]:9.700883611487832In[79]:(result['x'],[10,10])❸Out[79]:99.99999999999999
❶最优参数值(即最优投资组合)。
❷函数的最小负数值是最优解决方案值。
❸预算约束是有约束力的;投入所有财富。
11.3积分In[80]:[81]:deff(x):(x)+0.5*x
积分区间应该为[0.5,9.5],这就得出了公式11-4所示的定积分。
公式11-4示例函数的积分
下面的代码定义了求取积分的主要Python对象:
In[82]:x=(0,10)y=f(x)❶a=0.5❷b=9.5Ix=(a,b)❸Iy=f(Ix)❹
❶积分左界。
❷积分右界。
❸积分区间值。
❹积分函数值。
图11-15将积分值表示为函数下的灰色阴影区域:[1]
图11-15积分值表现为阴影面积
In[83]:[84]:fig,ax=(figsize=(10,6))(x,y,'b',linewidth=2)(bottom=0)Ix=(a,b)Iy=f(Ix)verts=[(a,0)]+list(zip(Ix,Iy))+[(b,0)]poly=Polygon(verts,facecolor='0.7',edgecolor='0.5')_patch(poly)(0.75*(a+b),1.5,r"$\int_a^bf(x)dx39;)(0.075,0.9,'$f(x)39;,'$b#39;))_yticks([f(a),f(b)]);11.3.1数值积分
子库包含一组精选的函数,可以计算给定上下限和数学函数下的数值积分。这些函数的例子包含用于固定高斯求积的_quad()、用于自适应求积的quad()和用于龙贝格积分的():
In[85]:_quad(f,a,b)[0]Out[85]:24.366995967084602In[86]:(f,a,b)[0]Out[86]:24.374754718086752In[87]:(f,a,b)Out[87]:24.374754718086713
还有一些积分函数以输入列表或者包含函数值和输入值的ndarray对象作为输入。这种函数的例子包括使用梯形法则的()和实现辛普森法则的():
In[88]:xi=(0.5,9.5,25)In[89]:(f(xi),xi)ut[89]:24.352733271544516In[90]:(f(xi),xi)Out[90]:24.37496418455075
11.3.2通过模拟求取积分
通过蒙特卡洛模拟(参见第12章)的期权和衍生物估值基于这样一个认识——可以通过模拟来求取积分。为此,在积分区间内取I个随机的x值,并计算每个随机x值处的积分函数值。加总所有函数值并求其平均值,就可以得到积分区间的平均函数值。将该值乘以积分区间长度,可以得出估算的积分值。
下面的代码说明蒙特卡洛估算积分值如何随着提取随机数个数的增加而收敛(但并非单调收敛)。即使提取的随机数个数较少,估算值也已经相当接近:
In[91]:foriinrange(1,20):(1000)x=(i*10)*(b-a)+a❶print((f(x))*(b-a))24.80476227933146326.522926.26554751922397626.0277033994382424.99954.886323.52791227484325323.50785765896120723.6723674606698923.67941041606288624.424404.23900534681905624.180224.42419198756672623.92493308053378324.1948421202787524.183324.10069092966227423.76905109847816
❶随机数x的值随每次循环增加。
本文截选自《Python金融大数据分析第2版》
《Python金融大数据分析第2版》分为5部分,共21章。第1部分介绍了Python在金融学中的应用,其内容涵盖了Python用于金融行业的原因、Python的基础架构和工具,以及Python在计量金融学中的一些具体入门实例;第2部分介绍了Python的基础知识以及Python中非常有名的库NumPy和pandas工具集,还介绍了面向对象编程;第3部分介绍金融数据科学的相关基本技术和方法,包括数据可视化、输入/输出操作和数学中与金融相关的知识等;第4部分介绍Python在算法交易上的应用,重点介绍常见算法,包括机器学习、深度神经网络等人工智能相关算法;第5部分讲解基于蒙特卡洛模拟开发期权及衍生品定价的应用,其内容涵盖了估值框架的介绍、金融模型的模拟、衍生品的估值、投资组合的估值等知识。
《Python金融大数据分析第2版》本书适合对使用Python进行大数据分析、处理感兴趣的金融行业开发人员阅读。