大模型(LLM)是一种人工智能模型,旨在理解和生成人类语言。它们在大量的文本数据上进行训练,可以执行广泛的任务,包括文本总结、翻译、情感分析等等。LLM的特点是规模庞大,包含数十亿的参数,帮助它们学习语言数据中的复杂模式。这些模型通常基于深度学习架构,如转化器,这有助于它们在各种NLP任务上取得令人印象深刻的表现。
本周精选了10篇LLM领域的优秀论文,为了方便大家阅读,只列出了论文标题、作者、AMinerAI综述等信息,如果感兴趣可扫码查看原文,PC端数据同步(收藏即可在PC端查看),每日新论文也可登录小程序查看。
1.COGVLM:VISUALEXPERTFORLARGELANGUAGEMODELS
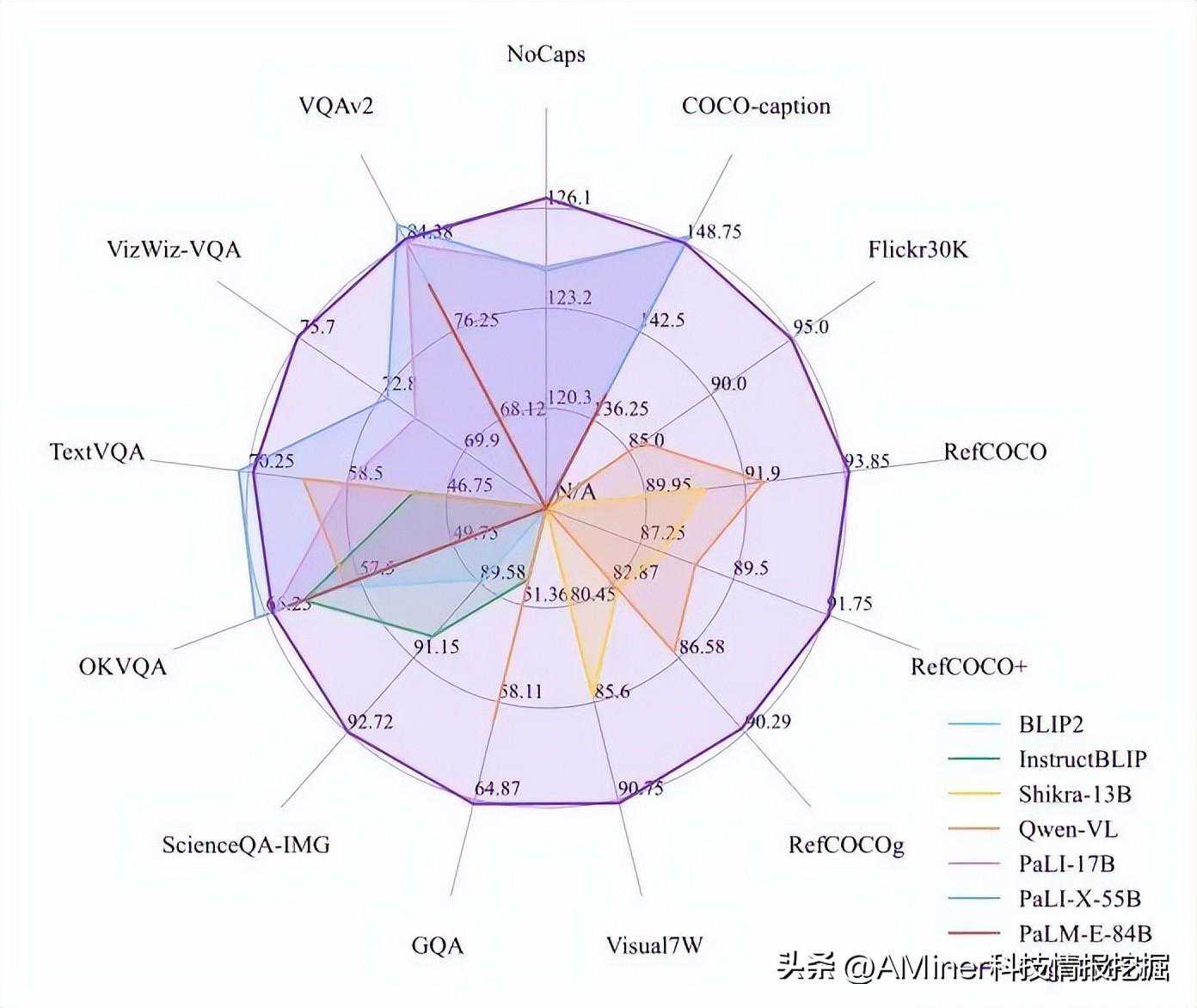
这篇论文介绍了CogVLM,一个强大的开源视觉语言基础模型。与流行的浅层对齐方法不同,CogVLM通过在注意力和FFN层中的可训练视觉专家模块,弥合了预训练语言模型和图像编码器之间的差距。因此,CogVLM能够在不牺牲NLP任务性能的情况下,实现视觉语言特征的深度融合。CogVLM-17B在10个经典的跨模态基准测试中取得了最先进的性能,包括NoCaps、Flicker30kcaptioning、RefCOCO、RefCOCO+、RefCOCOg、Visual7W、GQA、ScienceQA、VizWizVQA和TDIUC,并且在VQAv2、OKVQA、TextVQA、COCOcaptioning等任务中排名第二,超过了或与PaLI-X55B相媲美。
2.AutoGen:EnablingNext-GenLLMApplicationsviaMulti-AgentConversation
这篇论文介绍了一个名为AutoGen的新框架,它通过多智能体对话框架,使得使用大型语言模型(LLM)的应用程序开发成为可能。AutoGen的智能体是可定制的、可对话的,并且可以无缝地允许人类的参与。它们可以采用各种模式,结合LLM、人类输入和工具的使用。AutoGen的设计提供了多个优点:a)它优雅地解决了这些LLM强大的但有缺陷的生成和推理能力;b)它利用了人类的理解和智慧,同时通过对智能体之间的对话提供有价值的自动化;c)它简化了复杂LLM工作流程的实施,将其统一为自动化智能体对话。文中还提供了许多不同的例子,展示了开发人员如何使用AutoGen轻松有效地解决任务或构建应用程序,范围涵盖编程、数学、运筹学、娱乐、在线决策、问答等等。
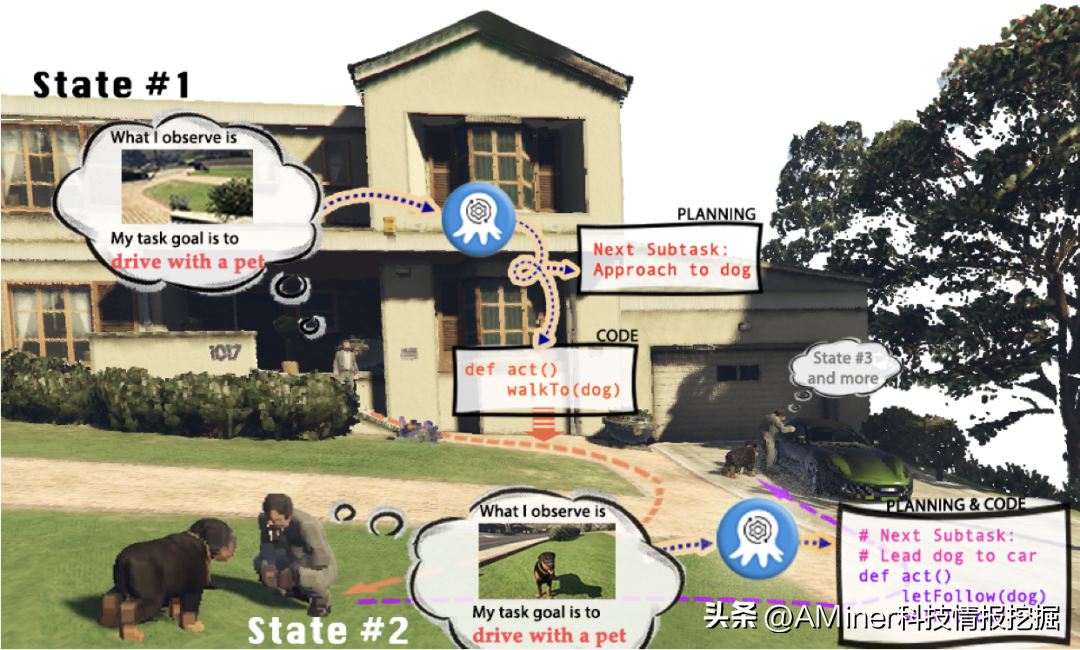
3.Octopus:EmbodiedVision-LanguageProgrammerfromEnvironmentalFeedback
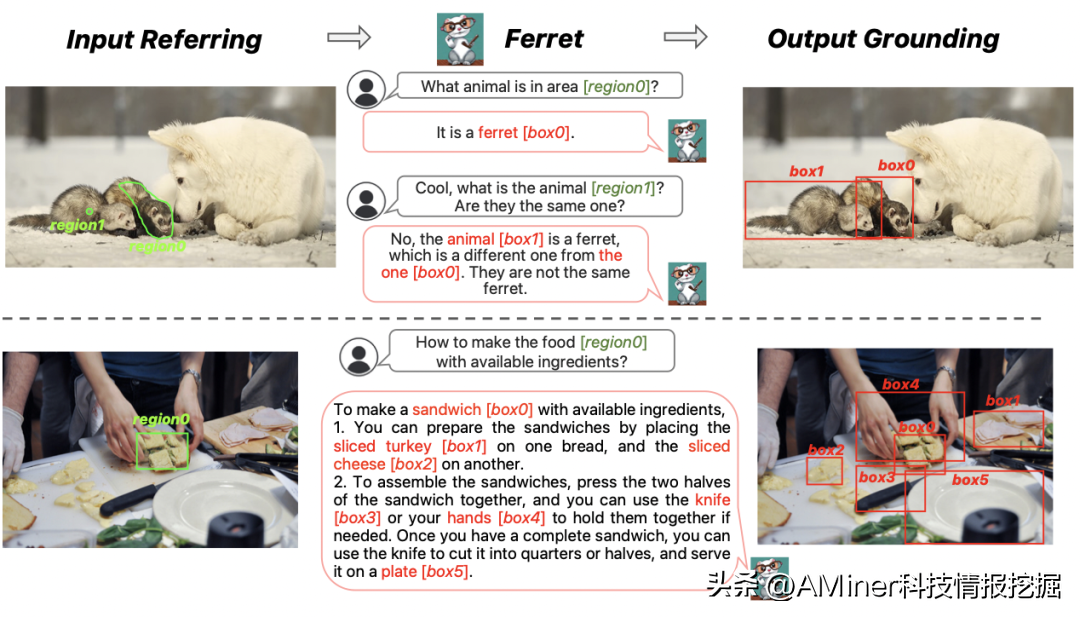
4.Ferret:ReferandGroundAnythingAnywhereatAnyGranularity
这篇论文介绍了一种名为Ferret的新型多模态大型语言模型(MLLM),可以理解图像中任何形状或粒度的空间指称,并准确地将开放词汇描述与实际位置进行关联。为了在LLM范式中统一指称和定位,Ferret采用了一种新颖且强大的混合区域表示方法,将离散坐标和连续特征整合在一起,表示图像中的区域。为了提取各种形状区域的连续特征,我们提出了一种空间感知视觉采样器,擅长处理不同形状之间的不同稀疏性。因此,Ferret可以接受各种区域输入,如点、边界框和自由形状。为了增强Ferret的能力,我们策划了GRIT数据集,这是一个包括110万样本的全面的指称和定位指令调整数据集,其中包含丰富的分层空间知识,以及9.5K难负数据以提高模型鲁棒性。最终得到的模型不仅在经典的指称和定位任务中表现优异,而且在基于区域和定位需求的多模态聊天中大大超越了现有的MLLM。我们的评估还发现,其描述图像细节的能力显著提高,对象错觉问题明显缓解。代码和数据将在。
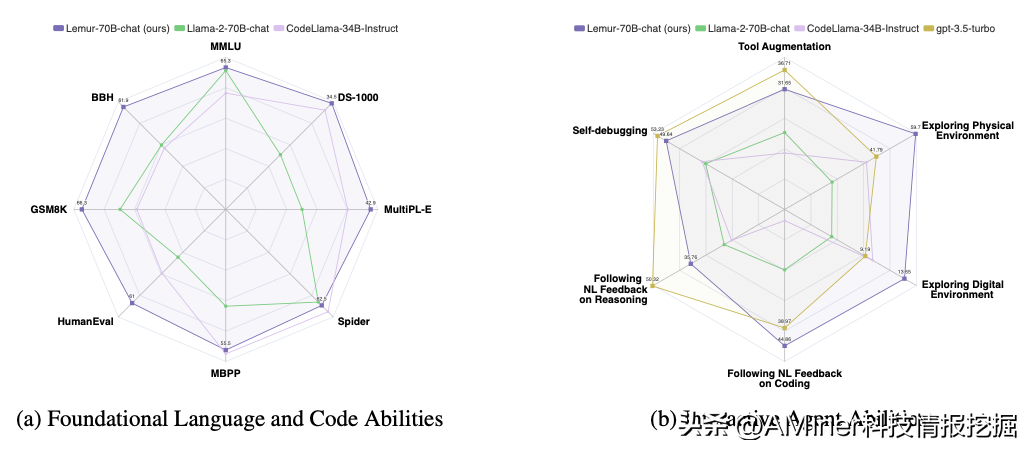
5.Lemur:HarmonizingNaturalLanguageandCodeforLanguageAgents
这篇论文介绍了Lemur和Lemur-Chat,这两个开源的语言模型在自然语言和编程能力方面都进行了优化,以作为多功能语言代理的骨干。从语言聊天模型到功能性语言代理的演变,要求模型不仅掌握人类互动、推理和规划,还要确保在相关环境中的地面性。这需要在模型中语言和编程能力的和谐结合。Lemur和Lemur-Chat就是为了解决这个必要性而提出的,它们在两个领域都表现出平衡的能力,与现有开源模型不同,这些模型往往只专注于其中一个领域。通过使用密集的代码语料库进行细致的预训练和在文本和代码数据上进行指令微调,我们的模型在各种文本和编码基准测试的公开开源模型中实现了最先进的平均性能。综合实验证明,Lemur在现有开源模型中具有优越性,并在涉及人类通信、工具使用和全观察和部分观察环境的各种代理任务方面表现出色。自然语言和编程语言之间的协调使Lemur-Chat在代理能力方面显著缩小了与专有模型之间的差距,为开发高级开源代理提供了关键见解,这些代理擅长推理、规划和在环境之间无缝操作。
6.LearnFromModelBeyondFine-Tuning:ASurvey

7.GameGPT:Multi-agentCollaborativeFrameworkforGameDevelopment
这篇论文介绍了一种名为GameGPT的多代理协作框架,用于自动游戏开发。该框架基于大型语言模型(LLM),已经展示出其自动化和加速软件开发过程的能力。然而,部署LLM在生产环境中的主要障碍之一是虚假信息。我们提出了另一种担忧:冗余。我们的框架提出了一系列方法来减轻这两个问题。这些方法包括双重协作和分层方法,以及一些内部词汇,以减轻计划、任务识别和实施阶段中的虚假信息和冗余。此外,还介绍了一种解耦方法,以实现代码生成时更好的精确度。
8.KwaiYiiMath:TechnicalReport

9.MatChat:ALargeLanguageModelandApplicationServicePlatformforMaterialsScience
这篇论文介绍了一款名为MatChat的大型语言模型与应用服务平台,专为材料科学设计。在材料科学研究中,预测化学合成路径起着关键作用。然而,合成路径的复杂性和缺乏全面的数据集目前阻碍了我们准确预测这些化学过程的能力。论文作者利用最近在生成式人工智能(GAI)方面的进展,包括自动文本生成、问答系统和微调技术,开发了针对特定领域的规模化AI模型。在本文中,作者利用LLaMA2-7B模型的力量,并通过学习过程融合了13,878条结构化材料知识数据,从而增强了该模型。这个名为MatChat的专有AI模型专注于预测无机材料合成路径,并在材料科学领域表现出卓越的知识生成和推理能力。尽管MatChat需要进一步优化以满足多样化的材料设计需求,但这项研究无疑突显了它在材料科学领域令人印象深刻的推理能力和创新潜力。MatChat现已上线并开放使用,模型及其应用框架均作为开源资源提供。这项研究为在材料科学中集成生成式AI的协同创新奠定了坚实的基础。
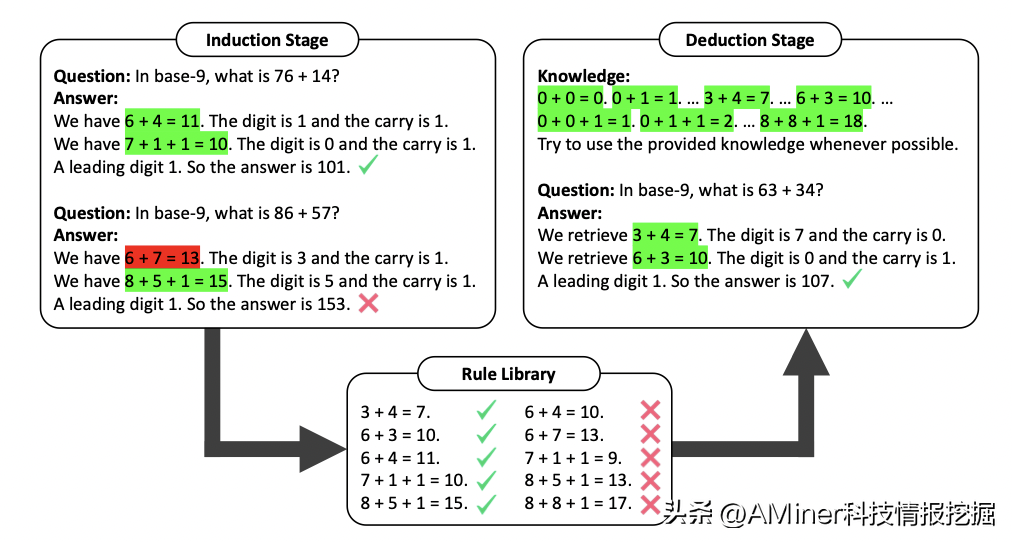
10.LargeLanguageModelscanLearnRules
这篇论文研究了大型语言模型(LLMs)在学习规则方面的应用。在给出一些示例和中间步骤的情况下,LLMs在各种推理任务中表现出令人印象深刻的效果。然而,当依赖LLM中的隐含知识时,提示方法通常会在隐含知识错误或与任务不一致的情况下产生错误的答案。为解决这个问题,作者提出了一个名为Hypotheses-to-Theories(HtT)的框架,该框架学习一个用于与LLMs进行推理的规则库。HtT包含两个阶段,即归纳阶段和演绎阶段。在归纳阶段,首先要求LLM在训练示例上生成并验证规则。足够频繁地出现在正确答案之前的规则被收集形成一个规则库。在演绎阶段,然后提示LLM使用学到的规则库进行推理以回答测试问题。实验结果表明,HtT在数值推理和关系推理问题上均优于现有的提示方法,准确率提高了11-27%。学到的规则也可以转移到不同模型和同一问题的不同形式上。
如何使用AMinerAI?
或者右下角便可进入ChatPaper页面。
在AMinerAI页面中,可以选择基于单篇文献进行对话和基于全库(个人文献库)对话,可选择上传本地PDF或者直接在AMiner上检索文献。
AMinerAI入口:「链接」